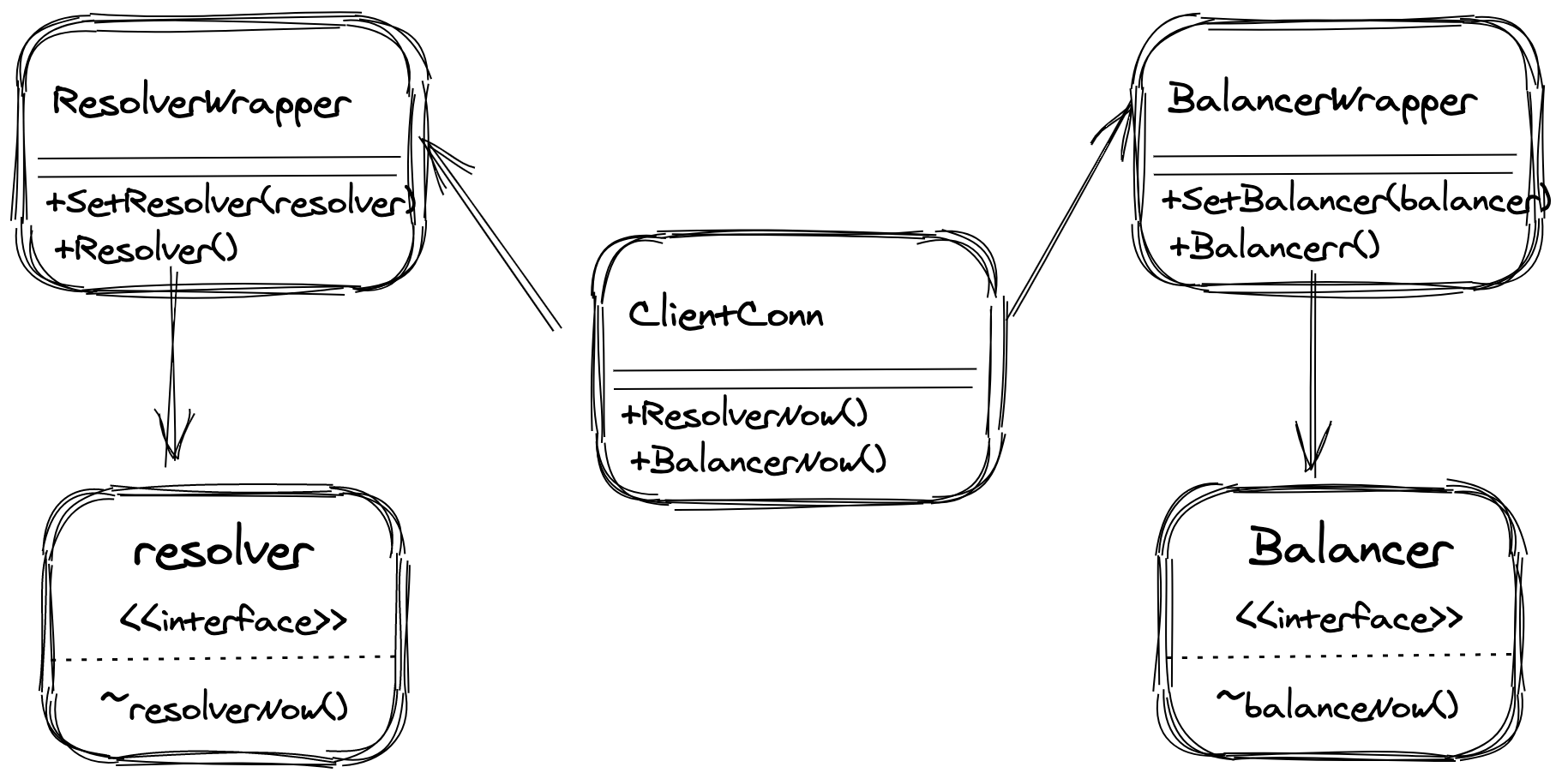
gRPC 客户端解析器和负载均衡器的交互
流程整理
在第一次建立连接时,gRPC 会调用服务端地址相对应的 Resolver,来解析出所有能够提供服务的服务端地址。随后,经过指定的 Balancer,选择其中的一个地址,建立连接。
如果是已经建立过连接,在 Resolver 中存在一个协程,监听了服务的状态,当存在新上线或下线的服务,会重新进行地址解析,来获取新的服务端地址集合,随后通过 Balancer 来选择一个地址,建立连接。
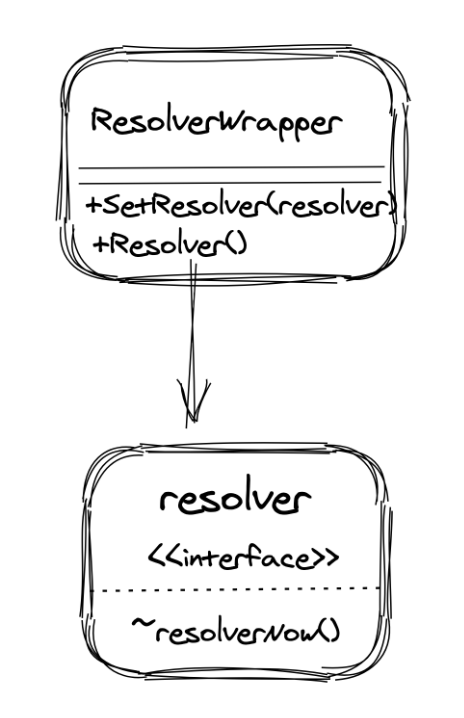
装饰器 Wrapper
gRPC 的 Resolver 和 Balancer 都是支持自定义的。我们可以自己定义各种不同的 Resolver 和 Balancer,来应对不同场景的需求。
这么做虽然增加了代码复杂度,但是却能够让 gRPC 变得更灵活,能够对各种复杂情景提供支持。
那么,要怎么才能够实现插件式的编程呢?
答案是使用装饰器模式。
装饰模式(Decorator)也叫包装器模式(Wrapper)。GOF在《设计模式》一书中给出的定义为:动态地给一个对象添加一些额外的职责。
装饰器模式是指动态地给一个对象添加一些额外的职责,就增加功能来说装饰模式比生成子类更为灵活。它通过创建一个包装对象,也就是装饰来包裹真实的对象。
首先创建一个 resolver 接口,并设计一些具体的 resolver 实现类:

然后我们还需要一个 resolver 的包装器,里面包含了真正的 resolver。
当我们的 gRPC 需要调用 ResolverNow 方法的时候,他只需要调用 resolverWrapper 中的 Resolve() 方法,在这个方法中来调用真正的 resoleNow() 逻辑:
解析器 Resolver
Resolver 称为解析器,能够将客户端传入的 “符合某种规则的名称” 解析为 IP 地址列表。假设你定义了一种地址格式:aaa:///bbb-project/ccc-srv
然后 Resolver 会将这个地址解析成好几个 ip:port,代表了提供 ccc-srv 服务集群的所有机器地址,这就是 Resolver 的作用。(也可以说 resolver 用来进行服务发现)
那么,Resolver 是怎么进行解析的呢?换句话说,Resolver是如何做到输入某种地址,输出一串IP地址呢?
这部分的工作需要由用户自己实现。
gRPC 提供的是插件式的 Resolver 功能,他会根据用户传入的 aaa:///bbb-project/ccc-srv,选择一个能够解析 aaa 的 Resolver,并进行解析,得到 ip:port 列表。
// Determine the resolver to use.
resolverBuilder, err := cc.parseTargetAndFindResolver()
//...
// Build the resolver.
rWrapper, err := newCCResolverWrapper(cc, resolverBuilder)
if err != nil {
return nil, fmt.Errorf("failed to build resolver: %v", err)
}
取得 Resolver
其中这里的 parseTargetAndFindResolver() 方法则承接了 Resolver 的获取
func (cc *ClientConn) parseTargetAndFindResolver() (resolver.Builder, error) {
// ...
var rb resolver.Builder
// 2.解析 target,
// 获取开发者传入的 target 参数的地址类型,在后续查找适合这种类型地址的 Resolver。
parsedTarget, err := parseTarget(cc.target)
if err != nil {
// ...
} else {
// 3.根据解析的target找到合适的 resolverBuilder
rb = cc.getResolver(parsedTarget.Scheme)
if rb != nil {
cc.parsedTarget = parsedTarget
return rb, nil
}
}
// 如果没有找到自定义的 resolver 则使用默认的 resolver
defScheme := resolver.GetDefaultScheme()
canonicalTarget := defScheme + ":///" + cc.target
parsedTarget, err = parseTarget(canonicalTarget)
if err != nil {
return nil, err
}
rb = cc.getResolver(parsedTarget.Scheme)
if rb == nil {
return nil, fmt.Errorf("could not get resolver for default scheme: %q", parsedTarget.Scheme)
}
cc.parsedTarget = parsedTarget
return rb, nil
}
其中这里的 parseTarget 用简单一句话来概括:获取开发者传入的 target 参数的地址类型(就是将其解析成 [scheme]://[authority]/endpoint 格式),在后续查找适合这种类型地址的 Resolver。
而这里的 getResolver 则是根据上面的 scheme 去查找相应的 Resolver
rb := cc.getResolver(cc.parsedTarget.Scheme)
// ...
func (cc *ClientConn) getResolver(scheme string) resolver.Builder {
// 先查看是否在配置中存在resolver
for _, rb := range cc.dopts.resolvers {
if scheme == rb.Scheme() {
return rb
}
}
// 如果配置中没有相应的resolver,再从注册的resolver中寻找
return resolver.Get(scheme)
}
// 可以看出,ResolverBuilder 是从m这个map里面找到的
func Get(scheme string) Builder {
if b, ok := m[scheme]; ok {
return b
}
return nil
}
Resolver 的注册
看到这里我们可以推测:对于每个 ResolverBuilder,是需要提前注册的。
如果不存在则会走默认的解析器 passthroughResolver,当然这个默认的解析器也是需要注册的,它在 init() 的时候注册了自己。
// internal/resolver/passthrough/passthrough.go
func init() {
resolver.Register(&passthroughBuilder{})
}
// 注册Resolver,即是把自己加入map中
func Register(b Builder) {
m[b.Scheme()] = b
}
ResolverWrapper 的创建
回到 ClientConn 的创建过程中,在获取到了 ResolverBuilder 之后,进行下一步的操作:
// Build the resolver.
rWrapper, err := newCCResolverWrapper(cc, resolverBuilder)
if err != nil {
return nil, fmt.Errorf("failed to build resolver: %v", err)
}
cc.mu.Lock()
cc.resolverWrapper = rWrapper
cc.mu.Unlock()
gRPC 为了实现插件式的 Resolver,因此采用了装饰器模式,创建了一个 ResolverWrapper。
func newCCResolverWrapper(cc *ClientConn, rb resolver.Builder) (*ccResolverWrapper, error) {
ccr := &ccResolverWrapper{
cc: cc,
done: grpcsync.NewEvent(),
}
// ...
// 根据传入的 Builder,创建 resolver,并放入 wrapper 中
ccr.resolver, err = rb.Build(cc.parsedTarget, ccr, rbo)
return ccr, nil
}
好,到了这里我们可以暂停一下。
我们停下来思考一下我们需要实现的功能:为了解耦 Resolver 和 Balancer,我们希望能够有一个中间的部分,接收到 Resolver 解析到的地址,然后对它们进行负载均衡。因此,在接下来的代码阅读过程中,我们可以带着这个问题:Resolver 和 Balancer 的通信过程是什么样的?
再看上面的代码,ClientConn 的创建已经结束了。那么我们可以推测,剩下的逻辑就在 rb.Build(cc.parsedTarget, ccr, rbo) 这一行代码里面。
Resolver 的创建,Build 并不是一个确定的方法,他是一个接口。
type Builder interface {
Build(target Target, cc ClientConn, opts BuildOptions) (Resolver, error)
}
在创建 Resolver 的时候,我们需要在 Build 方法里面初始化 Resolver 的各种状态。并且,因为 Build 方法中有一个 target 的参数,我们会在创建 Resolver 的时候,需要对这个 target 进行解析。
也就是说,创建 Resolver 的时候,会进行第一次的域名解析。并且,这个解析过程,是由开发者自己设计的。
到了这里我们会自然而然的接着考虑,解析之后的结果应该保存为什么样的数据结构,又应该怎么去将这个结果传递下去呢?
我们拿最简单的 passthroughResolver 来举例:
func (*passthroughBuilder) Build(target resolver.Target, cc resolver.ClientConn, opts resolver.BuildOptions) (resolver.Resolver, error) {
r := &passthroughResolver{
target: target,
cc: cc,
}
// 创建 Resolver 的时候,进行第一次的解析
r.start()
return r, nil
}
// 对于 passthroughResolver 来说,正如他的名字,直接将参数作为结果返回
func (r *passthroughResolver) start() {
r.cc.UpdateState(resolver.State{Addresses: []resolver.Address{{Addr: r.target.Endpoint}}})
}
我们可以看到,对于一个 Resolver,需要将解析出的地址,传入 resolver.State 中,然后调用 r.cc.UpdateState 方法。
那么这个 r.cc.UpdateState 又是什么呢?
他就是我们上面提到的 ccResolverWrapper。
这个时候逻辑就很清晰了,gRPC 的 ClientConn 通过调用 ccResolverWrapper 来进行域名解析,而具体的解析过程则由开发者自己决定。在解析完毕后,将解析的结果返回给 ccResolverWrapper。
负载均衡器 Balancer
Balancer 称为负载均衡器,负责在 Resolver 解析出的一串地址中,选择其中的一个建立连接。
cc.balancerWrapper = newCCBalancerWrapper(cc, balancer.BuildOptions{
DialCreds: credsClone,
CredsBundle: cc.dopts.copts.CredsBundle,
Dialer: cc.dopts.copts.Dialer,
Authority: cc.authority,
CustomUserAgent: cc.dopts.copts.UserAgent,
ChannelzParentID: cc.channelzID,
Target: cc.parsedTarget,
})
我们因此也可以进行推测:在 ccResolverWrapper 中,会将解析出的结果以某种形式传递给 Balancer。
func (ccr *ccResolverWrapper) UpdateState(s resolver.State) {
...
// 将Resolver解析的最新状态保存下来
ccr.curState = s
// 对状态进行更新
ccr.poll(ccr.cc.updateResolverState(ccr.curState, nil))
}
关于 poll 方法这里就不提了,重点我们看 ccr.cc.updateResolverState(ccr.curState, nil) 这部分。
这里的 ccr.cc 中的 cc,就是我们创建的 ClientConn 对象。
也就是说,此时 Resolver 解析的结果,最终又回到了 ClientConn 中。
注意,对于 updateResolverState 方法,在源码中逻辑比较深,主要是为了处理各种情况。在这里我直接把核心的那部分贴出来,所以这部分的代码你可以理解为是伪代码实现,和原本的代码是有出入的。如果你希望看到具体的实现,你可以去阅读gRPC的源码。
func (cc *ClientConn) updateResolverState(s resolver.State, err error) error {
var newBalancerName string
// 假设已经配置好了balancer,那么使用配置中的balancer
if cc.sc != nil && cc.sc.lbConfig != nil {
newBalancerName = cc.sc.lbConfig.name
}
// 否则的话,遍历解析结果中的地址,来判断应该使用哪种balancer
else {
var isGRPCLB bool
for _, a := range addrs {
if a.Type == resolver.GRPCLB {
isGRPCLB = true
break
}
}
if isGRPCLB {
newBalancerName = grpclbName
} else if cc.sc != nil && cc.sc.LB != nil {
newBalancerName = *cc.sc.LB
} else {
newBalancerName = PickFirstBalancerName
}
}
// 具体的balancer逻辑
cc.switchBalancer(newBalancerName)
// 使用balancerWrapper更新Client的状态
bw := cc.balancerWrapper
uccsErr := bw.updateClientConnState(&balancer.ClientConnState{ResolverState: s, BalancerConfig: balCfg})
return ret
}
我们再来康康 switchBalancer 到底做了什么:
func (cc *ClientConn) switchBalancer(name string) {
...
builder := balancer.Get(name)
cc.curBalancerName = builder.Name()
cc.balancerWrapper = newCCBalancerWrapper(cc, builder, cc.balancerBuildOpts)
}
是不是有一种似曾相识的感觉?
没错,这部分的代码,跟 ResolverWrapper 的创建过程很接近。都是获取到对应的 Builder Name,然后通过 name 来获取对应的 Builder,然后创建 wrapper。
func newCCBalancerWrapper(cc *ClientConn, b balancer.Builder, bopts balancer.BuildOptions) *ccBalancerWrapper {
ccb := &ccBalancerWrapper{
cc: cc,
scBuffer: buffer.NewUnbounded(),
done: grpcsync.NewEvent(),
subConns: make(map[*acBalancerWrapper]struct{}),
}
go ccb.watcher()
ccb.balancer = b.Build(ccb, bopts)
return ccb
}
同样的,Build 具体的 Balancer 的过程,也是由开发者自己决定的。
详细流程总结
创建 ClientConn 的时候创建 ResolverWrapper,由 ClientConn 通知 ResolverWrapper 进行域名解析。
此时,ResolverWrapper 会将这个请求交给真正的 Resolver,由真正的 Resolver 来处理域名解析。
解析完毕后,Resolver 会将结果保存在 ResolverWrapper 中,ResolverWrapper 再将这个结果返回给 ClientConn。
当 ClientConn 发现解析的结果发生了改变,那么他就会去通知 BalancerWrapper,重新进行负载均衡。此时 BalancerWrapper 又会去让真正的 Balancer 做这件事,最终将结果返回给 ClientConn。
我们画张图来展示这个过程: